
简可信离线批量OCR识别
v2.1.0.0 绿色版- 软件大小:134 MB
- 软件语言:简体中文
- 更新时间:2022-11-28
- 软件类型:国产软件 / 文字处理
- 运行环境:WinXP, Win7, Win8, Win10, WinAll
- 软件授权:免费软件
- 官方主页:http://www.gaya-soft.cn/
- 软件等级 :
- 介绍说明
- 下载地址
- 精品推荐
- 相关软件
- 网友评论
简可信图片批量OCR识别软件提供简单的文字识别功能,打开图像到软件就可以立即点击识别功能读取图像上的文字,从而将其输出为PDF或者是TXT格式,方便用户复制文本内容使用,您可以将多张图像添加到软件转换为PDF文档,将拍摄的文档照片,截图的内容添加到软件就可以选择识别导出为双层的PDF文件,以后就可以通过PDF格式查看图像内容了,内置专业的ocr模板识别工具,可以快速识别各种证件关键信息,可以识别发票扫描、高拍仪关键信息,也可以在软件编辑新的识别模板,方便识别指定的内容。
软件功能
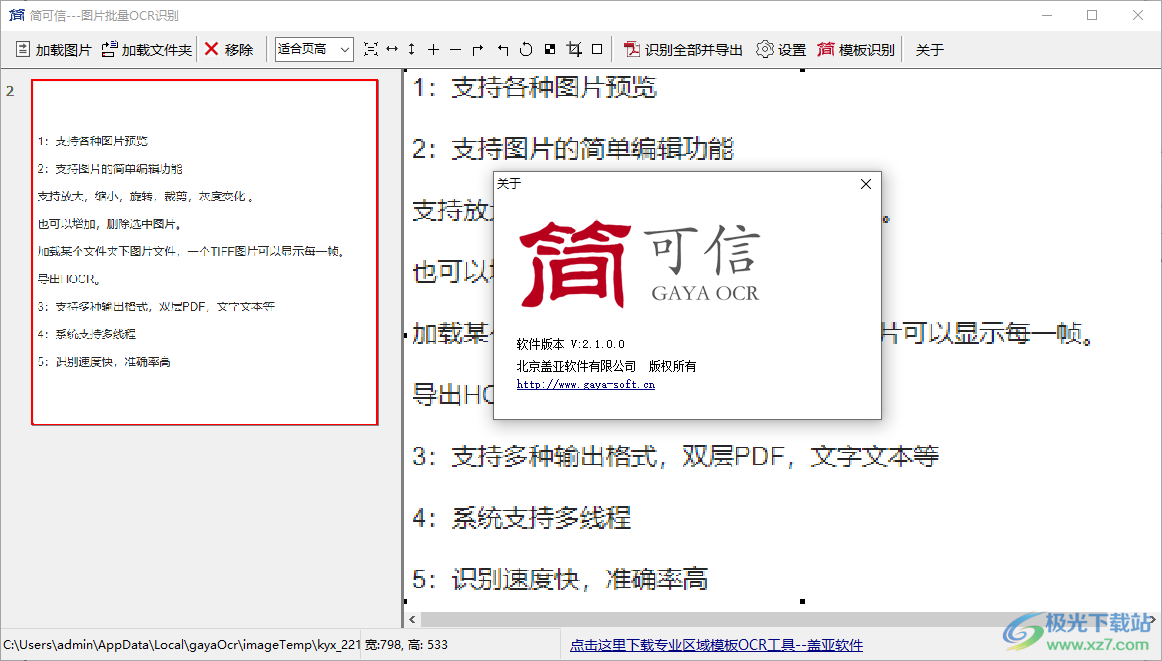
1、可以同时对大量PDF文档,图片文件进行OCR识别。
2、将您的图片文档,PDF文件转换为可编辑的文本,可以批量输出双层PDF,文本文件等。
3、软件使用Tesseract5 API, 速度快,质量高,支持多线程处理。
4、本系统可以实现内网环境下本地化部署,不需要把文件上传到互联网,可以保障文件安全,不会导致泄密。
5、软件完全免费,没有任何时间和功能限制。
软件特色
1、简可信图片批量OCR识别软件可以帮助用户轻松识别文本内容
2、如果你的图像上有文本内容就可以选择识别
3、可以将各种纸质的文件拍照,随后导入图像到软件识别
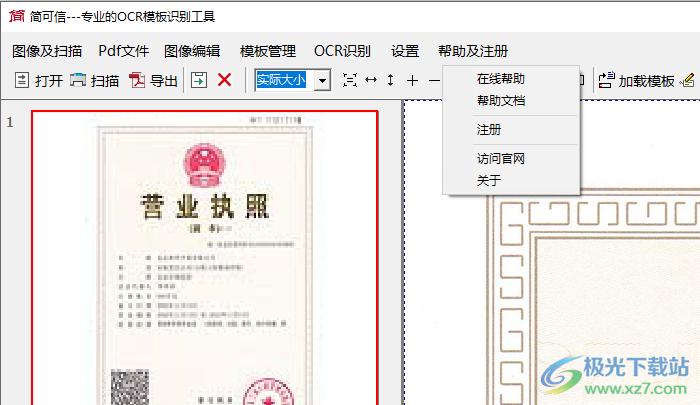
4、各种营业执照、证件信息、书本信息都可以通过拍照的方式添加到软件识别
5、可以批量加载图像到软件识别,可以轻松查看识别的文字
6、可以在软件预览图像,可以调整适合当前页面的宽度和高度,方便预览图像中的文字
7、支持中文、英文识别,可以手动配置百度API识别文字
使用方法
1、将软件安装到电脑,地址是C:UsersadminAppDataLocalgayaOcr
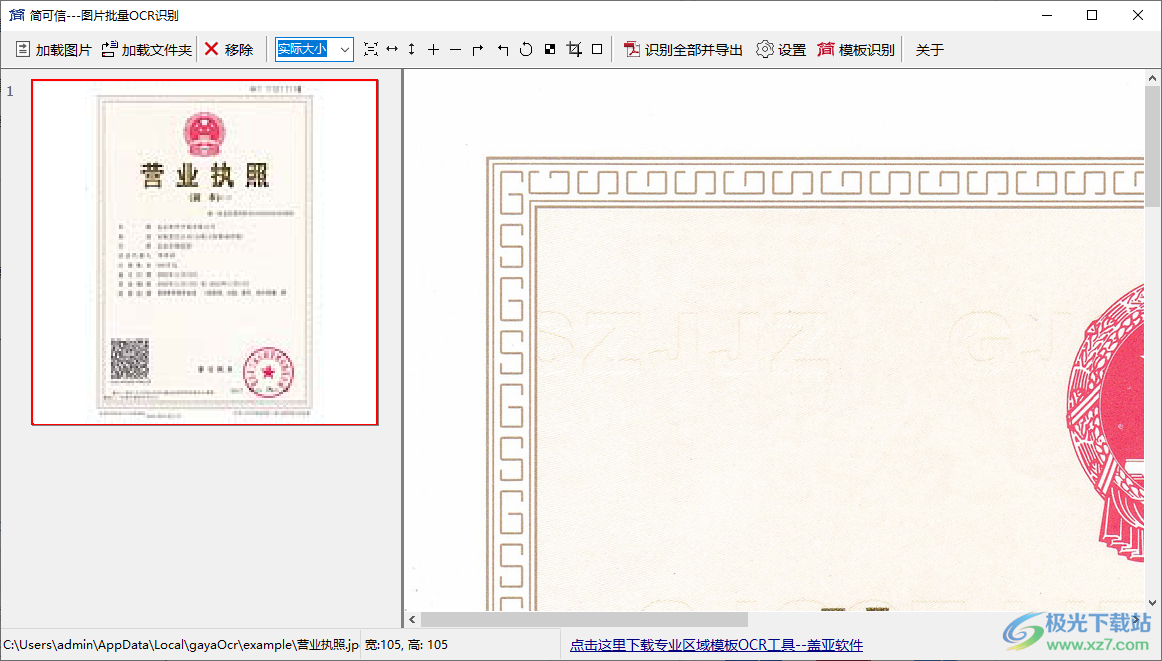
2、添加需要识别的内容,可以将图像添加到软件
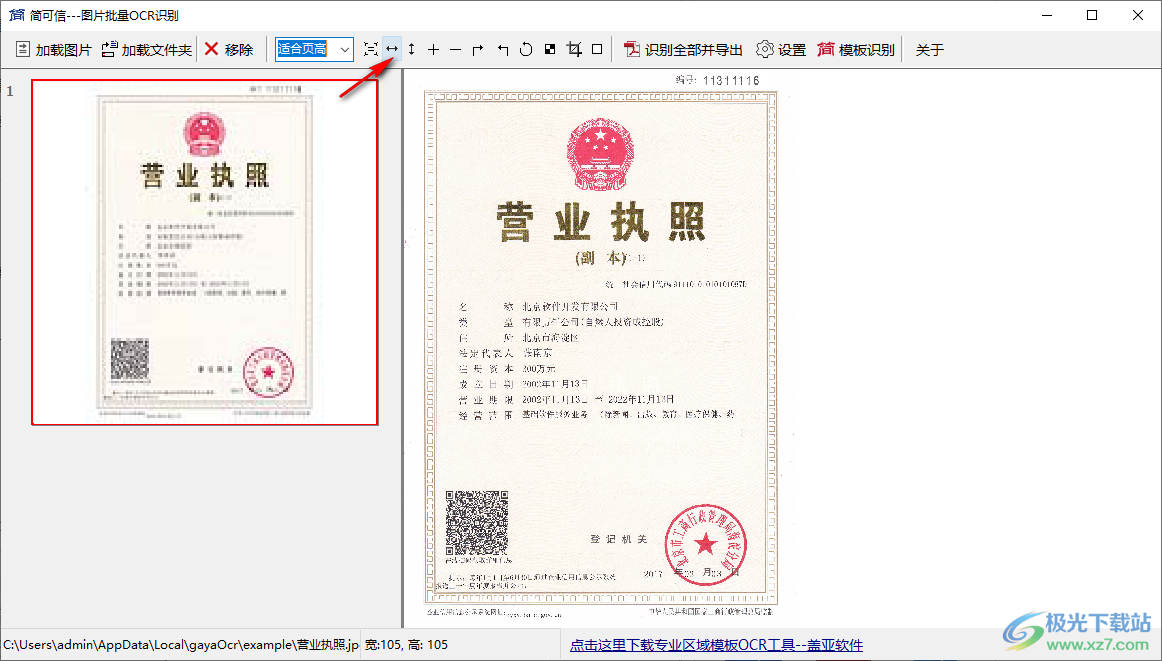
3、在顶部可以调整图像到适合的页面宽度以及页面高度,也可以自由缩放图像
4、点击识别全部并导出功能,弹出保存选项界面,可以选择保存为PDF,可以选择导出ocr识别文本
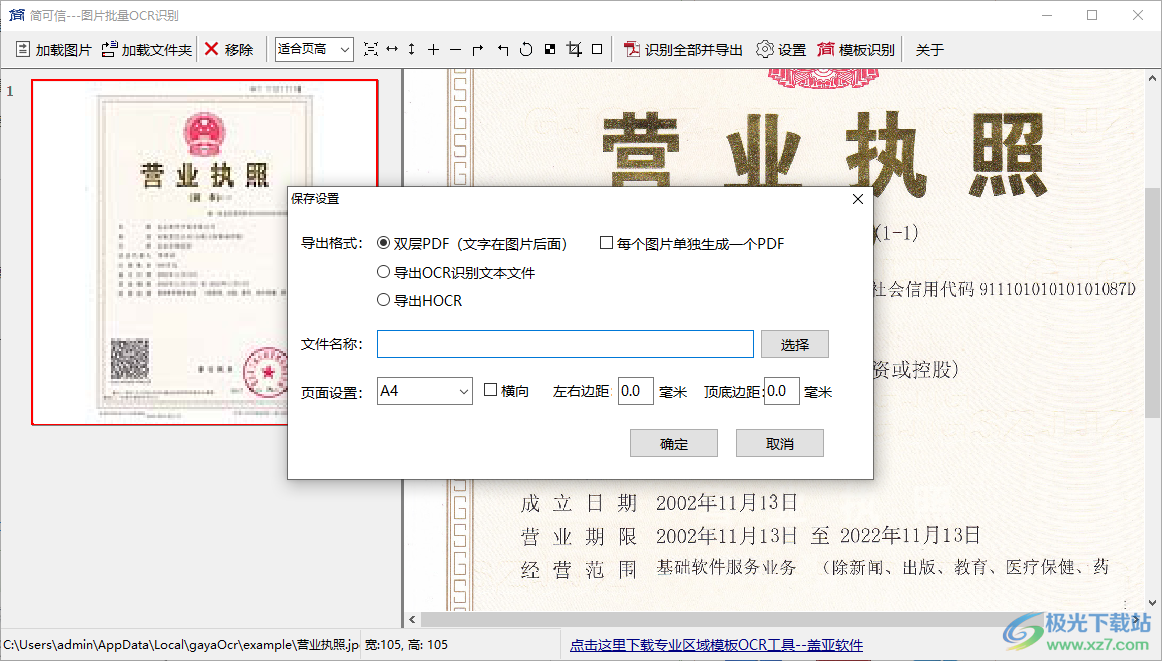
5、如果需要保存为TXT就选择导出ocr识别文本,也可以选择将图片单独生成PDF
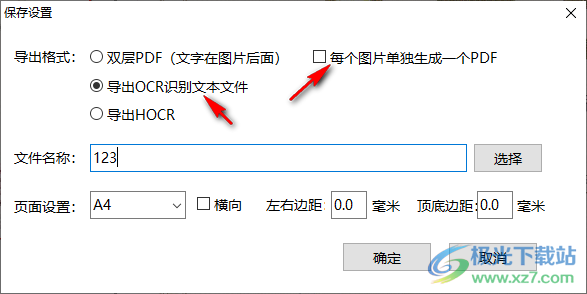
6、识别全部任务完毕,可以进入软件安装地址找到输出的文本
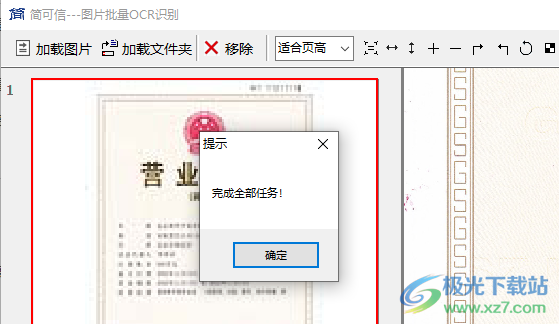
7、在C:UsersadminAppDataLocalgayaOcrbin地址下就可以查看到识别完毕的TXT,如果您选择保存PDF,这里就会显示PDF文件
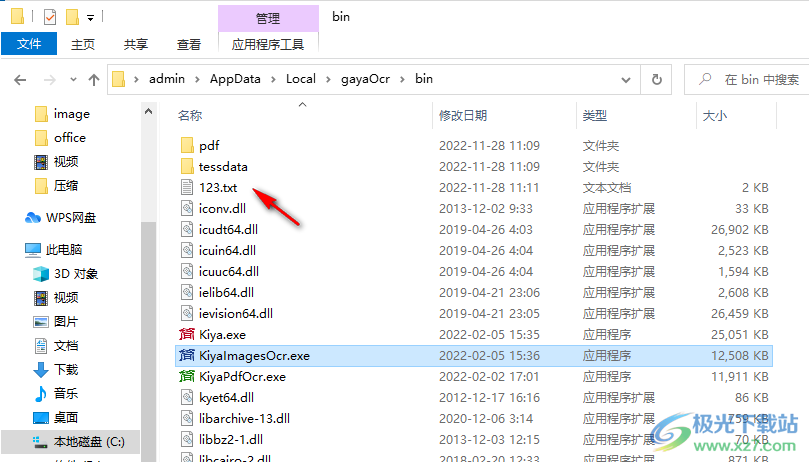
8、识别的效果就是这样的,无法精准识别文字内容
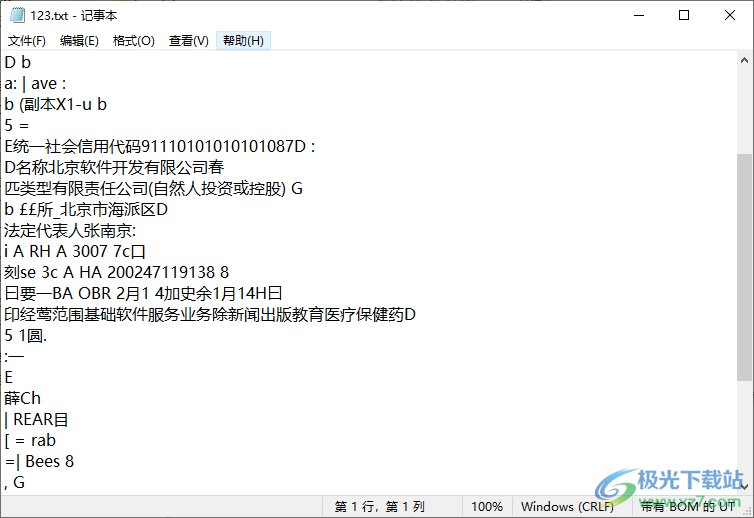
9、如果添加的是英文的内容就可以进入设置界面选择识别英文,可以设置识别线程数
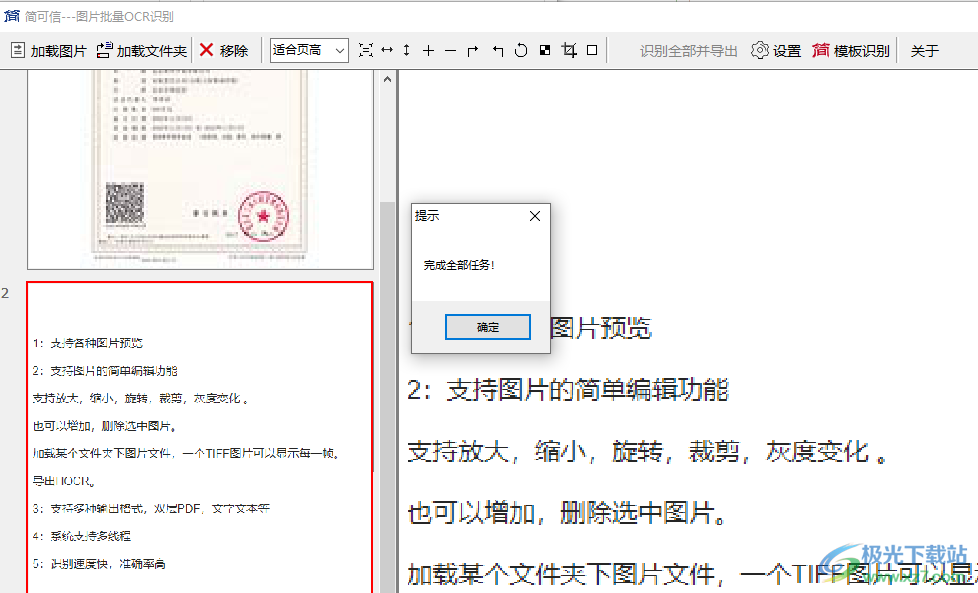
10、可以继续加载其他图像到软件识别,也可以在右上角启动“模板识别”功能
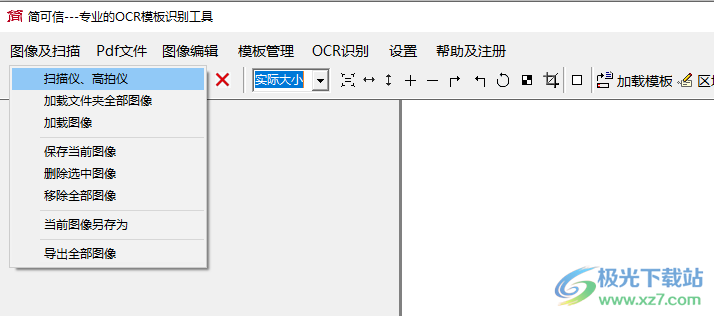
11、进入专业的ocr模板识别工具界面,支持扫描仪、高拍仪、加载文件夹全部图像、加载图像
12、编辑单页OCR识别模板、增加多页OCR识别模板、当前图片识别保存为模板、模板管理、打开模板文件夹、上传下载模板(服务器)
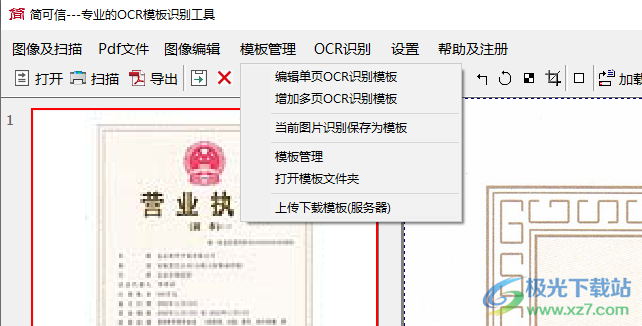
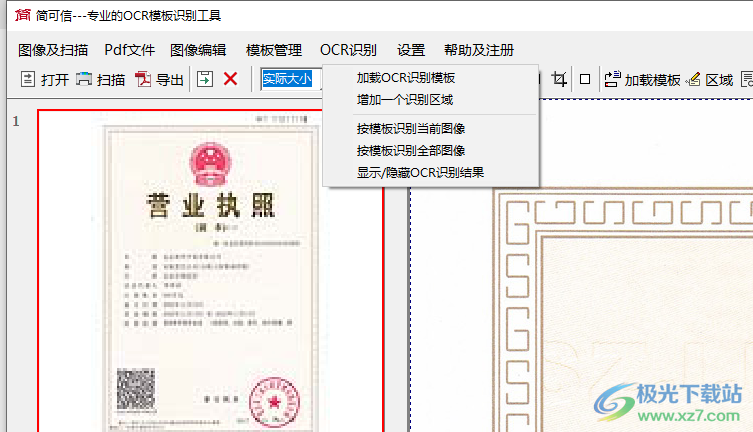
13、加载OCR识别模板、增加一个识别区域、按模板识别当前图像、按模板识别全部图像、显示/隐藏OCR识别结果
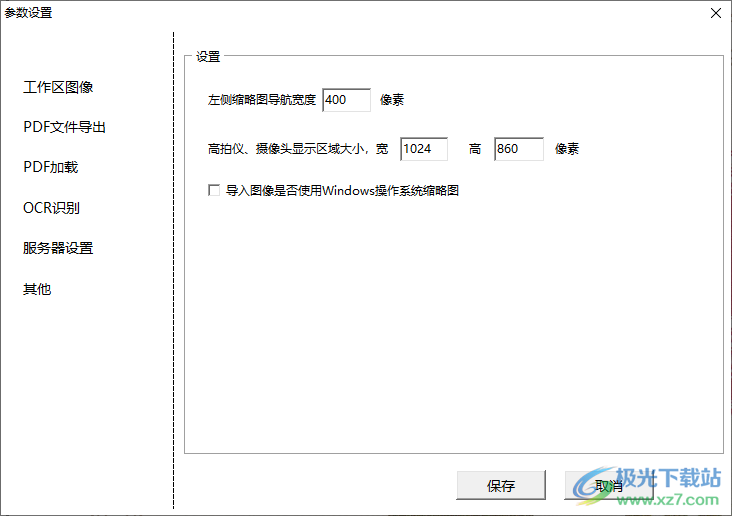
14、设置界面:左侧缩略图导航宽度400像素、高拍仪、摄像头显示区域大小,宽1024高860像素、导入图像是否使用Windows操作系统缩略图
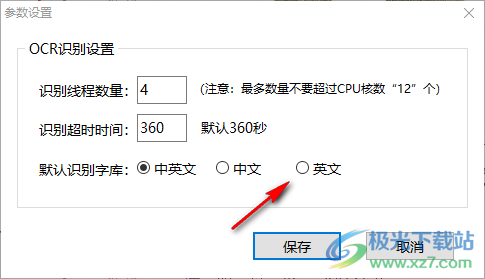
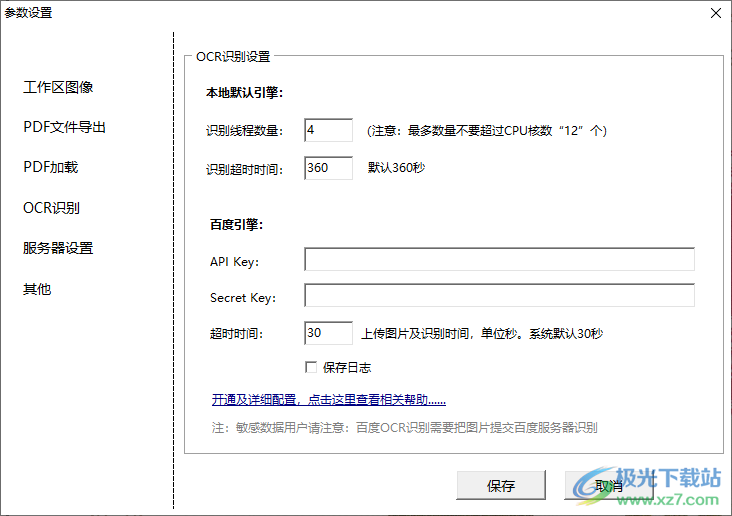
15、OCR识别设置
本地默认引擎:
识别线程数量:4(注意:最多数量不要超过CPU核数“12”个)
识别超时时间:360,默认360秒
百度引擎:可以在这里配置API
16、如果需要查看更多的功能可以点击在线帮助,可以查看帮助文档,可以进入官方网站
下载地址
- Pc版
简可信离线批量OCR识别 v2.1.0.0 绿色版
本类排名
本类推荐










装机必备
换一批























- 聊天
- qq电脑版
- 微信电脑版
- yy语音
- skype
- 视频
- 腾讯视频
- 爱奇艺
- 优酷视频
- 芒果tv
- 剪辑
- 爱剪辑
- 剪映
- 会声会影
- adobe premiere
- 音乐
- qq音乐
- 网易云音乐
- 酷狗音乐
- 酷我音乐
- 浏览器
- 360浏览器
- 谷歌浏览器
- 火狐浏览器
- ie浏览器
- 办公
- 钉钉
- 企业微信
- wps
- office
- 输入法
- 搜狗输入法
- qq输入法
- 五笔输入法
- 讯飞输入法
- 压缩
- 360压缩
- winrar
- winzip
- 7z解压软件
- 翻译
- 谷歌翻译
- 百度翻译
- 金山翻译
- 英译汉软件
- 杀毒
- 360杀毒
- 360安全卫士
- 火绒软件
- 腾讯电脑管家
- p图
- 美图秀秀
- photoshop
- 光影魔术手
- lightroom
- 编程
- python
- c语言软件
- java开发工具
- vc6.0
- 网盘
- 百度网盘
- 阿里云盘
- 115网盘
- 天翼云盘
- 下载
- 迅雷
- qq旋风
- 电驴
- utorrent
- 证券
- 华泰证券
- 广发证券
- 方正证券
- 西南证券
- 邮箱
- qq邮箱
- outlook
- 阿里邮箱
- icloud
- 驱动
- 驱动精灵
- 驱动人生
- 网卡驱动
- 打印机驱动


网友评论