
爬山虎采集器
v3.0.3.9 官方版- 软件大小:60.4 MB
- 软件语言:简体中文
- 更新时间:2022-11-01
- 软件类型:国产软件 / 下载工具
- 运行环境:WinXP, Win7, Win8, Win10, WinAll
- 软件授权:免费软件
- 官方主页:https://www.51pashanhu.com/docs/export/
- 软件等级 :
- 介绍说明
- 下载地址
- 精品推荐
- 相关软件
- 网友评论
爬山虎采集器是一款数据采集软件,可以帮助用户自动采集网络上的资源,将资源地址复制到软件就可以按照步骤采集数据,最后将采集的数据下载到电脑上保存使用,例如可以直接对京东商品列表采集,可以对京东商品评论采集,也可以采集新闻,支持采集博客园新闻、采集新浪新闻采集,让用户可以轻松获取指定网站上的内容,批量采集数据到电脑继续使用,这款软件使用还是比较简单的,启动软件就可以新建采集任务,输入采集地址就可以按照步骤执行下一步,操作过程还是很简单的,按照引导步骤就可以执行采集任务,需要就下载吧!
软件功能
1、使用点击式界面,在几分钟内从任何网站抓取数据。
2、适用于各种网站,能够采集互联网99%的网站,包括单页应用、Ajax加载等等动态类型网站
3、支持各种结构的网页数据,并且保存到Txt、excel以及数据库中。
4、它能够采集互联网上的大部分网站数据,并且将数据导出为各种格式的文件或者数据库,比如csv、excel、mysql、sqlserver、sqlite、access,甚至可以通过指定接口发布到你的网站。
5、快速高效,内置一套高速浏览器内核,加上HTTP引擎模式,实现快速采集数据
6、自动识别列表数据,通过智能算法,一键提取数据。
7、自动识别分页技术,通过算法智能识别、采集分页数据
8、混合浏览器引擎和HTTP引擎,兼顾了易用性和效率。
软件特色
1、爬山虎采集器可以轻松采集网页上的数据,在软件新建任务就可以开始采集
2、可以对多个站点内容采集,直接在软件输入多个地址一次采集
3、支持查看采集的页面,软件自动读取网页上的内容,将可采集的内容显示在列表
4、可以设置过滤方式,删除不需要采集的内容
5、大部分网站都可以采集。可以采集需要登录的网站
6、支持多个页面识别,如果你输入的地址有多个页面就可以自动识别分页内容
7、可以在软件选择对页面上的图像下载,可以选择对数据处理
8、支持文本替换、正则匹配、清除HTML标签、添加前后缀、字符转码、执行JavaScript等数据处理功能
9、支持执行C#代码、正文提取、字符映射、HTTP请求等数据处理功能
10、支持过滤设置:修改名称、删除字段、选择元素、添动加新元素、手动设置XPatl、设置取值属性
11、支持文件下载、使用自定义值、增量更新、取值属性、浏览器引擎和HTTP引|擎、POST请求等功能
12、支持自定义数据、批量生成起始网址、来集前执行脚本、JSON数据来集
使用说明
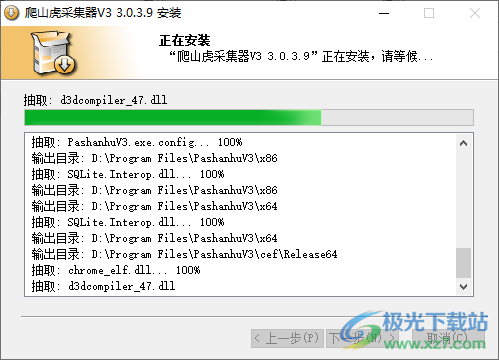
1、将爬山虎采集器直接安装到电脑,等待软件安装结束
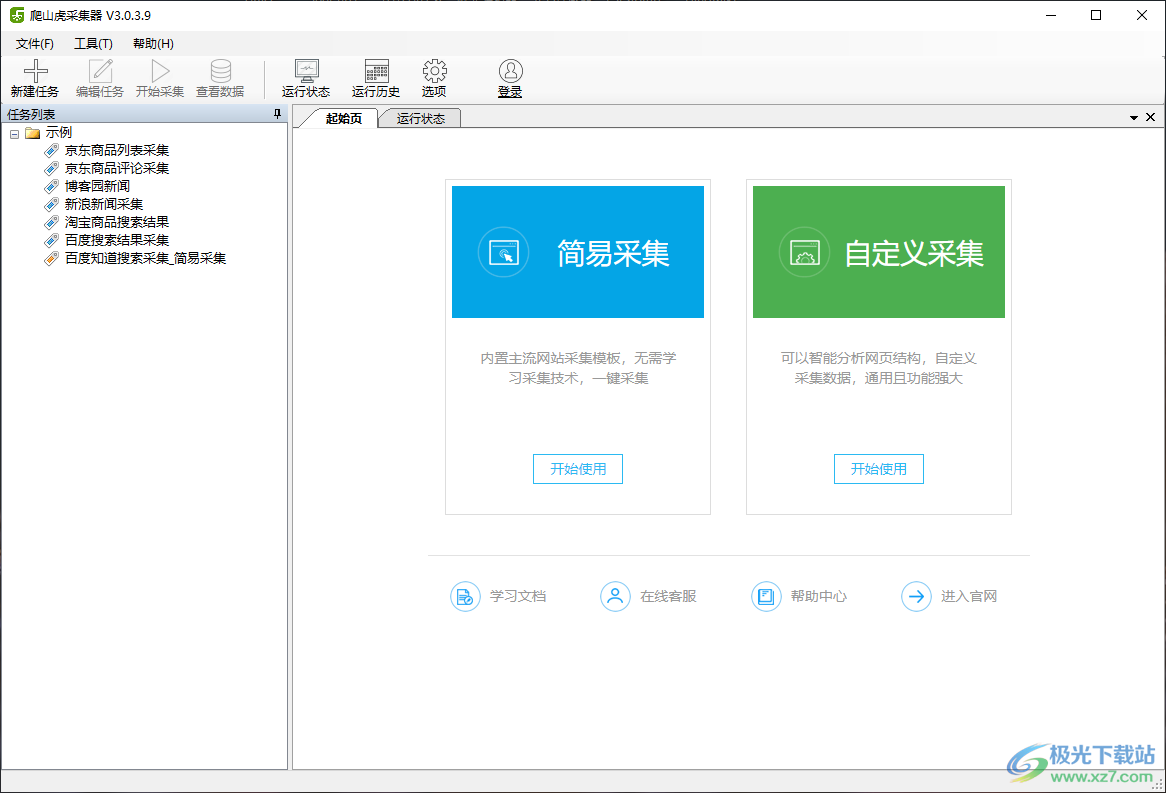
2、可以选择简易采集,可以选择自定义采集
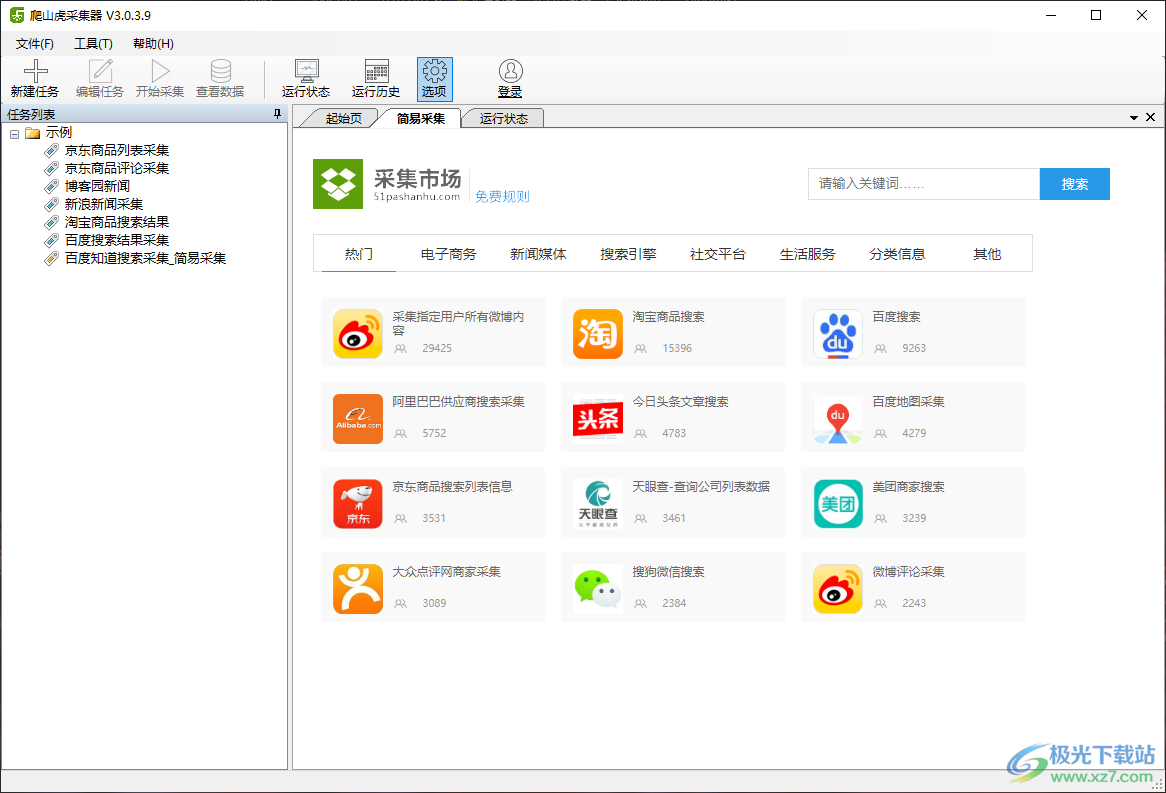
3、进入简易采集界面,这里是软件的其他功能界面,如果有需要就可以点击使用
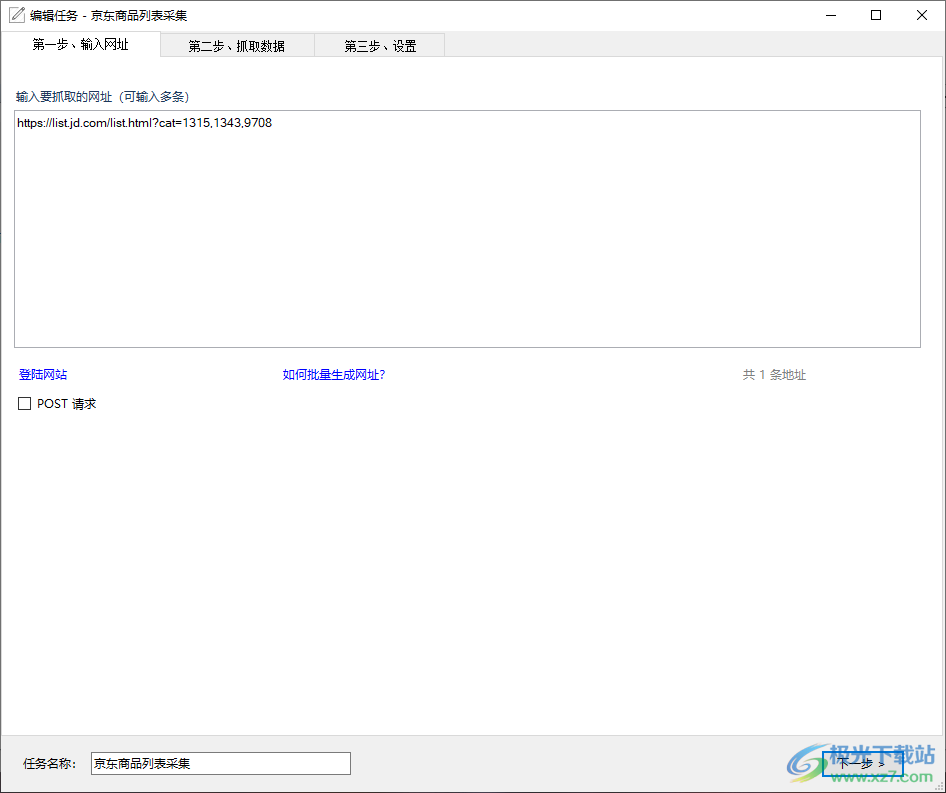
4、点击新建任务就可以进入地址设置界面,将需要采集的地址输入到软件,点击下一步
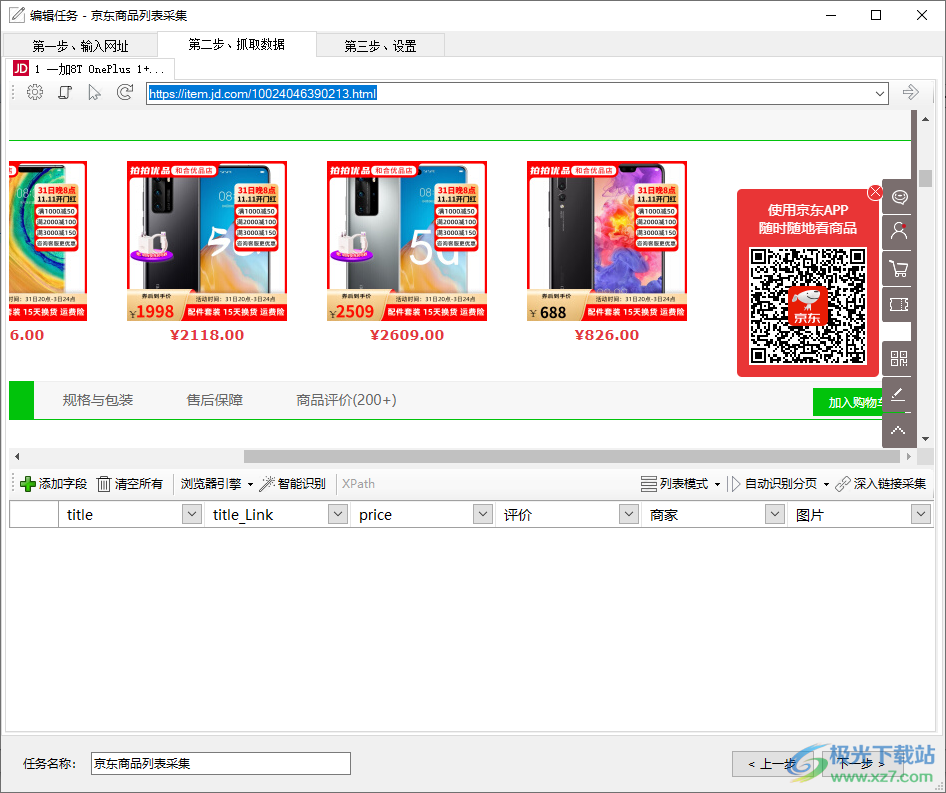
5、这里是数据抓取的界面,自动识别当前的网页内容,如果识别到数据就在软件底部列表显示,点击下一步
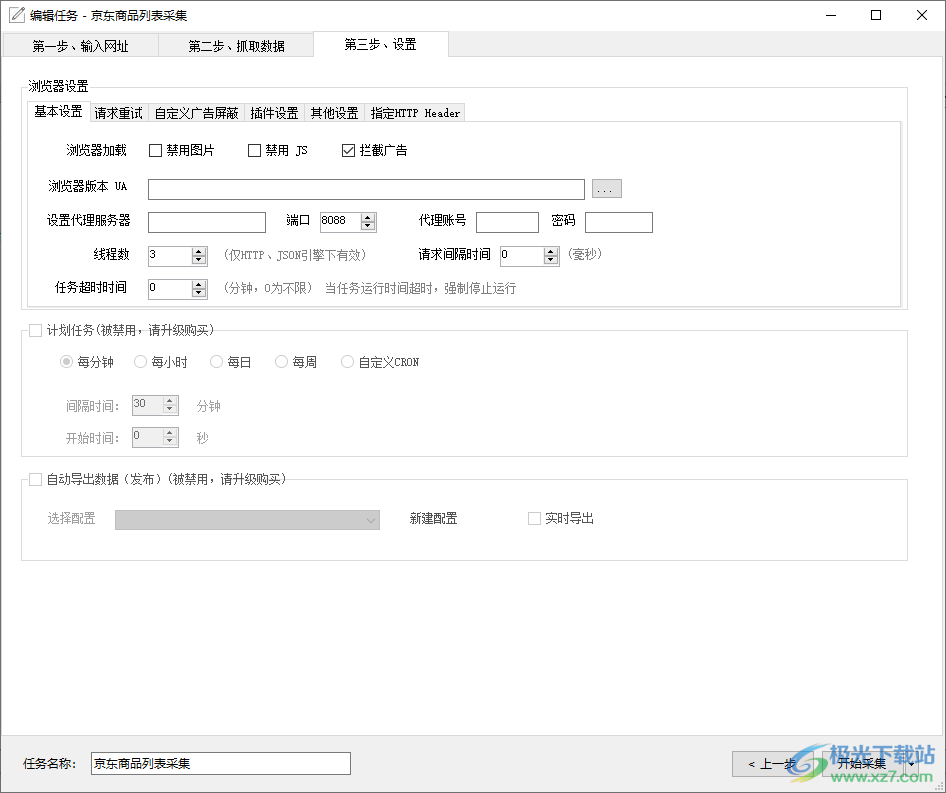
6、设置一些采集的参数,支持浏览器设置,支持代理服务器设置,支持自动采集计划任务设置
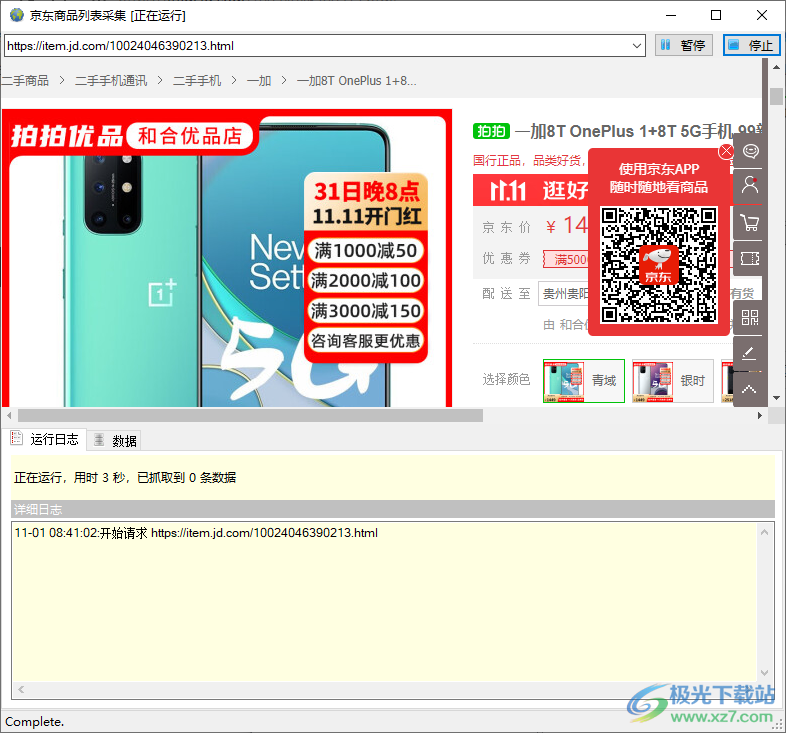
7、开始采集,软件自动分区页面上可以采集的数据,等待采集结束就可以导出数据
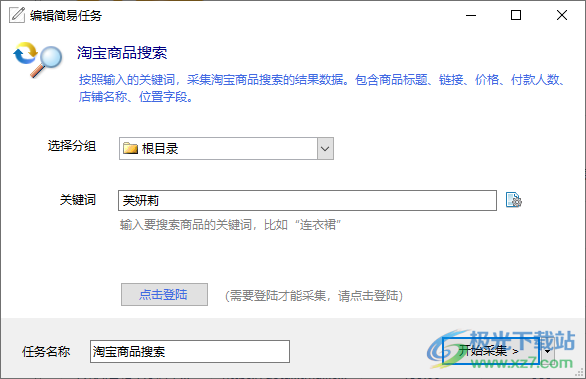
8、淘宝商品搜索
按照输入的关键词,采集淘宝商品搜索的结果数据。包含商品标题、链接、价格、付款人数店铺名称、位置字段。
9、如果对软件不了解可以点击帮助文档查看官方提供的教程,从而学习各种功能的操作方式
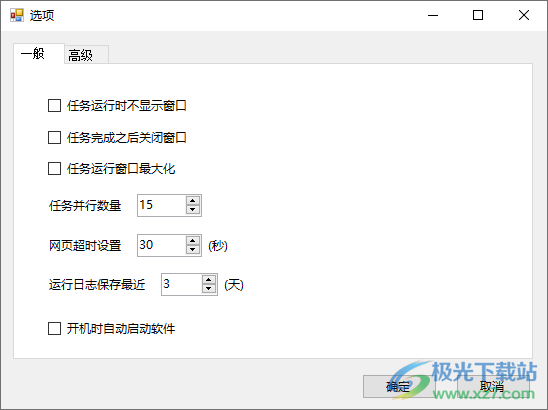
10、任务运行时不显示窗口、任务完成之后关闭窗口、任务运行窗口最大化
任务并行数量15
网页超时设置30(秒)
运行日志保存最近3(天)
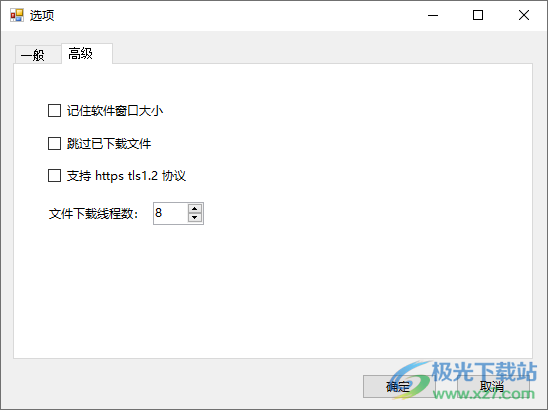
11、记住软件窗口大小
跳过已下载文件
支持https tls 1.2协议
文件下载线程数:8
官方教程
数据导出
爬山虎采集器支持多个格式的数据导出(发布),包括TXT、CSV、Excel、Access、MySQL、SQLServer、SQLite以及发布到网站接口(Api)。
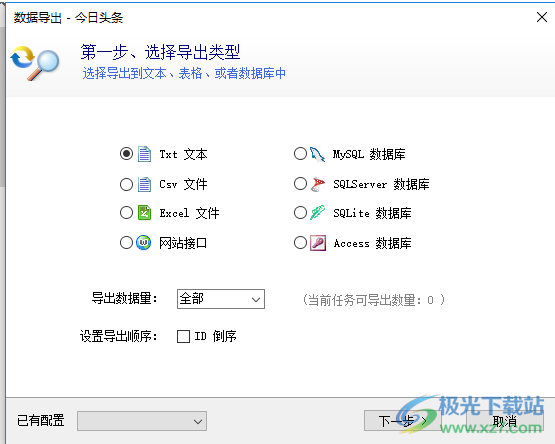
导出方式有2种:
手动导出,通过右击任务-> 导出任务,或者是在查看数据中导出。
自动导出,在编辑任务的第三步中设置导出。
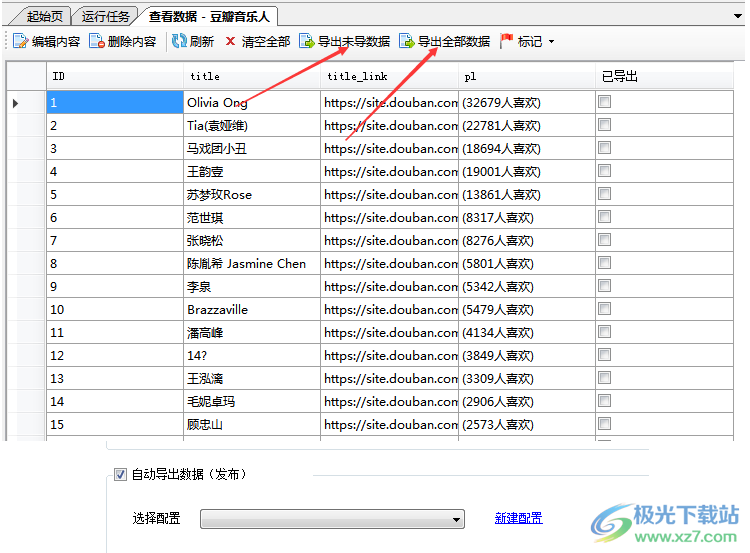
在数据导出后,会被标记为已导出,在下次导出时,不会再导出。 如果想要导出全部数据,而不区分已导出,可以在查看数据中选择导出全部。
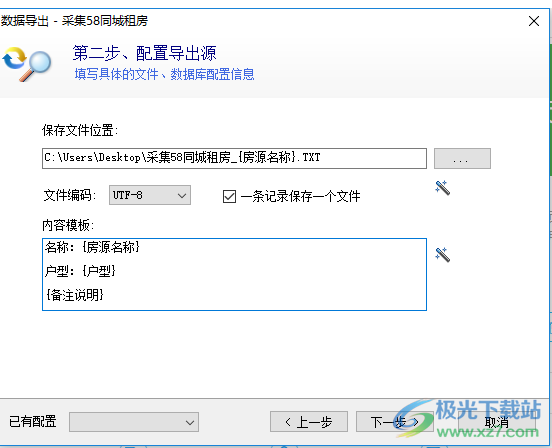
导出到Excel、CSV、TXT
可以将数据导出到Excel、CSV、TXT文件中,每次导出将会生成新的文件。 软件支持对导出的文件名设置变量,目前有2种格式变量,按照任务名和日期格式。
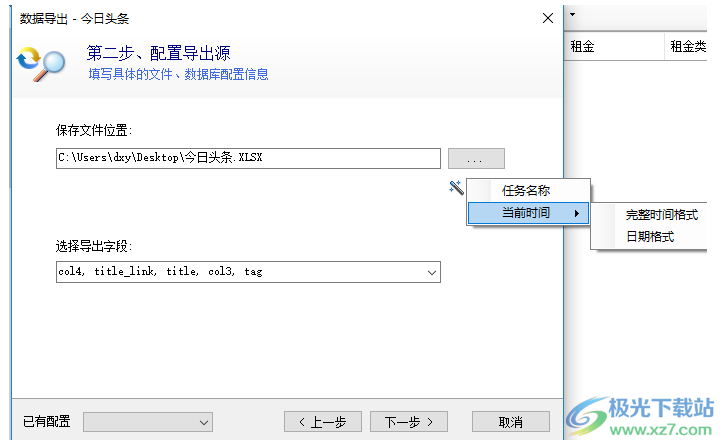
导出TXT目前支持一条记录保存为一个文件。可以根据字段值来定义文件名称,导出的内容格式也可以自定义模板
下载地址
- Pc版
爬山虎采集器 v3.0.3.9 官方版
本类排名
本类推荐









装机必备
换一批























- 聊天
- qq电脑版
- 微信电脑版
- yy语音
- skype
- 视频
- 腾讯视频
- 爱奇艺
- 优酷视频
- 芒果tv
- 剪辑
- 爱剪辑
- 剪映
- 会声会影
- adobe premiere
- 音乐
- qq音乐
- 网易云音乐
- 酷狗音乐
- 酷我音乐
- 浏览器
- 360浏览器
- 谷歌浏览器
- 火狐浏览器
- ie浏览器
- 办公
- 钉钉
- 企业微信
- wps
- office
- 输入法
- 搜狗输入法
- qq输入法
- 五笔输入法
- 讯飞输入法
- 压缩
- 360压缩
- winrar
- winzip
- 7z解压软件
- 翻译
- 谷歌翻译
- 百度翻译
- 金山翻译
- 英译汉软件
- 杀毒
- 360杀毒
- 360安全卫士
- 火绒软件
- 腾讯电脑管家
- p图
- 美图秀秀
- photoshop
- 光影魔术手
- lightroom
- 编程
- python
- c语言软件
- java开发工具
- vc6.0
- 网盘
- 百度网盘
- 阿里云盘
- 115网盘
- 天翼云盘
- 下载
- 迅雷
- qq旋风
- 电驴
- utorrent
- 证券
- 华泰证券
- 广发证券
- 方正证券
- 西南证券
- 邮箱
- qq邮箱
- outlook
- 阿里邮箱
- icloud
- 驱动
- 驱动精灵
- 驱动人生
- 网卡驱动
- 打印机驱动







网友评论